Using Spatial Bayesian methods in `cityClimateHealth`
bayesian_demo.RmdAnother way that this model can be solved is by using Bayesian inference, implemented in STAN. We are including this implementation here so that it makes sense why we are including it later on.
The innovation here is combining the method of Armstrong 2014 with a spatial method, in this case BYM2.
We implemented the spatial bayesian method of BYM2 but instead of regular poisson as a conditional poisson (i.e., multinomial) which has performance gains that they articulate in Amrstrong.
This requires bringing in a shapefile, so you can define the network.
The standard application is using MCMC, we also include all STAN model types:
- MCMC
- laplace
- variational
- pathfinder
You can also experiment with speeding things up (at the risk of less precise estimates) using the laplace or variational method. see Jack’s notes as so what is going on here
Sb, basically a combination of these two things: https://academic.oup.com/ije/article/53/3/dyae061/7654027?guestAccessKey= https://link.springer.com/article/10.1186/1471-2288-14-122
A reminder that this data is simulated.
library(data.table)
#>
#> Attaching package: 'data.table'
#> The following object is masked from 'package:base':
#>
#> %notin%
data("ma_exposure")
data("ma_deaths")
# create exposure matrix
exposure_columns <- list(
"date" = "date",
"exposure" = "tmax_C",
"geo_unit" = "TOWN20",
"geo_unit_grp" = "COUNTY20"
)
TOWNLIST <- c('CHELSEA', 'EVERETT', 'REVERE', 'MALDEN')
exposure <- subset(ma_exposure, TOWN20 %in% TOWNLIST)
exposure_mat <- make_exposure_matrix(exposure,
exposure_columns,
time_subset = list(
month = 5:9,
year = 2012:2015
))
#> -- NA values automatically removed
#> > grp_level == FALSE, so using geo_unit as strata
#> strata dt_by = 'day', setting strata as geo_unit:yr:mn:dow
# create outcome table
outcome_columns <- list(
"date" = "date",
"outcome" = "daily_deaths",
"factor" = 'age_grp',
"factor" = 'sex',
"geo_unit" = "TOWN20",
"geo_unit_grp" = "COUNTY20"
)
deaths <- subset(ma_deaths, TOWN20 %in% TOWNLIST)
deaths_tbl <- make_outcome_table(deaths, outcome_columns,
time_subset = list(
month = 5:9,
year = 2012:2015
))
#> > No factors to collapse to, using all data
#> > grp_level == FALSE, so using geo_unit as strata
#> Missing outcome values introduced by xgrid were set to 0;
#> assumes that every time in the dataset should have an outcome value
#> strata dt_by = 'day', setting strata as geo_unit:yr:mn:dow
# plot
data("ma_towns")
library(ggplot2)
local_shp <- subset(ma_towns, TOWN20 %in% TOWNLIST)
ggplot(local_shp) + geom_sf(aes(fill = TOWN20))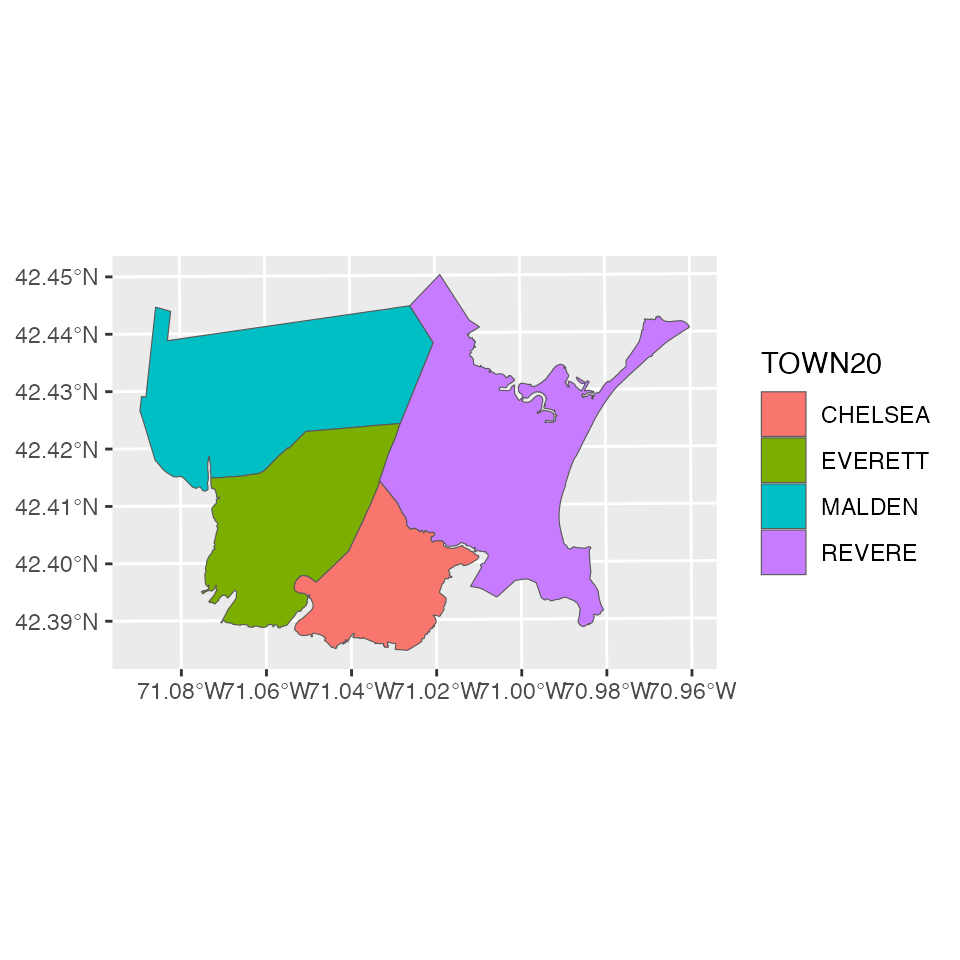
Now get initial estimates for each geo_unit
beta_l <- vector("list", 4)
cr_l <- vector("list", 4)
plot_l <- vector("list", 4)
cb_list <- vector("list", 4)
oo_list <- vector("list", 4)
for(bb in 1:4) {
m1 <- condPois_1stage(
subset(exposure_mat, TOWN20 == TOWNLIST[bb]),
subset(deaths_tbl, TOWN20 == TOWNLIST[bb]),
global_cen = 15)
cb_list[[bb]] <- m1$`_`$out[[1]]$orig_basis
oo_list[[bb]] <- m1$`_`$out[[1]]$outcomes
beta_l[[bb]] <- m1$`_`$out[[1]]$orig_coef
cr_l[[bb]] <- m1$`_`$out[[1]]$coef
plot_l[[bb]] <- plot(m1)
}
#>
#> crossbasis args for geo_unit CHELSEA :
#>
#> maxlag: 5
#>
#> argvar:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: Named num [1:2] 25.8 31.3
#> ..- attr(*, "names")= chr [1:2] "50%" "90%"
#>
#> arglag:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: num [1:2] 0.878 2.095
#>
#> strata:
#> CHELSEA:yr2012:mn05:dow03
#> strata_min: 0
#>
#>
#> crossbasis args for geo_unit EVERETT :
#>
#> maxlag: 5
#>
#> argvar:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: Named num [1:2] 25.8 31
#> ..- attr(*, "names")= chr [1:2] "50%" "90%"
#>
#> arglag:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: num [1:2] 0.878 2.095
#>
#> strata:
#> EVERETT:yr2012:mn05:dow03
#> strata_min: 0
#>
#>
#> crossbasis args for geo_unit REVERE :
#>
#> maxlag: 5
#>
#> argvar:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: Named num [1:2] 25.1 30.1
#> ..- attr(*, "names")= chr [1:2] "50%" "90%"
#>
#> arglag:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: num [1:2] 0.878 2.095
#>
#> strata:
#> REVERE:yr2012:mn05:dow03
#> strata_min: 0
#>
#>
#> crossbasis args for geo_unit MALDEN :
#>
#> maxlag: 5
#>
#> argvar:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: Named num [1:2] 24.4 29
#> ..- attr(*, "names")= chr [1:2] "50%" "90%"
#>
#> arglag:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: num [1:2] 0.878 2.095
#>
#> strata:
#> MALDEN:yr2012:mn05:dow03
#> strata_min: 0
mx <- do.call(cbind, beta_l) # COEFS NOT THE SAME
colnames(mx) = TOWNLIST
mx
#> CHELSEA EVERETT REVERE MALDEN
#> cbv1.l1 0.0451309468 0.05298088 -0.0005224117 0.017711625
#> cbv1.l2 -0.0223211761 -0.03592669 0.0184129771 0.012490790
#> cbv1.l3 0.0873424413 0.08593669 0.1029649763 0.093454486
#> cbv1.l4 -0.0335859603 -0.03578575 -0.0337628164 -0.041517343
#> cbv2.l1 0.0852368471 0.05049362 -0.0533811289 0.039648824
#> cbv2.l2 0.0166508607 -0.11934992 0.0747314454 0.055829432
#> cbv2.l3 0.1926712791 0.18510476 0.1393985118 0.118837565
#> cbv2.l4 -0.0462482063 -0.04542133 -0.0608086198 -0.054356689
#> cbv3.l1 0.0170645385 0.07301390 0.0257165131 0.038563344
#> cbv3.l2 -0.0005616437 -0.06948122 0.0223225434 -0.002010598
#> cbv3.l3 0.1718665757 0.12512136 0.1186064940 0.130222731
#> cbv3.l4 -0.0490847643 -0.01913613 -0.0655887549 -0.044893272
mcr <- do.call(cbind, cr_l) # COEFS THE SAME
colnames(mcr) = TOWNLIST
mcr
#> CHELSEA EVERETT REVERE MALDEN
#> b1 0.1847675 0.1774954 0.2034421 0.1922760
#> b2 0.4637942 0.3065562 0.2523009 0.2921484
#> b3 0.3375227 0.2624969 0.2438566 0.2749740
library(patchwork)
wrap_plots(plot_l)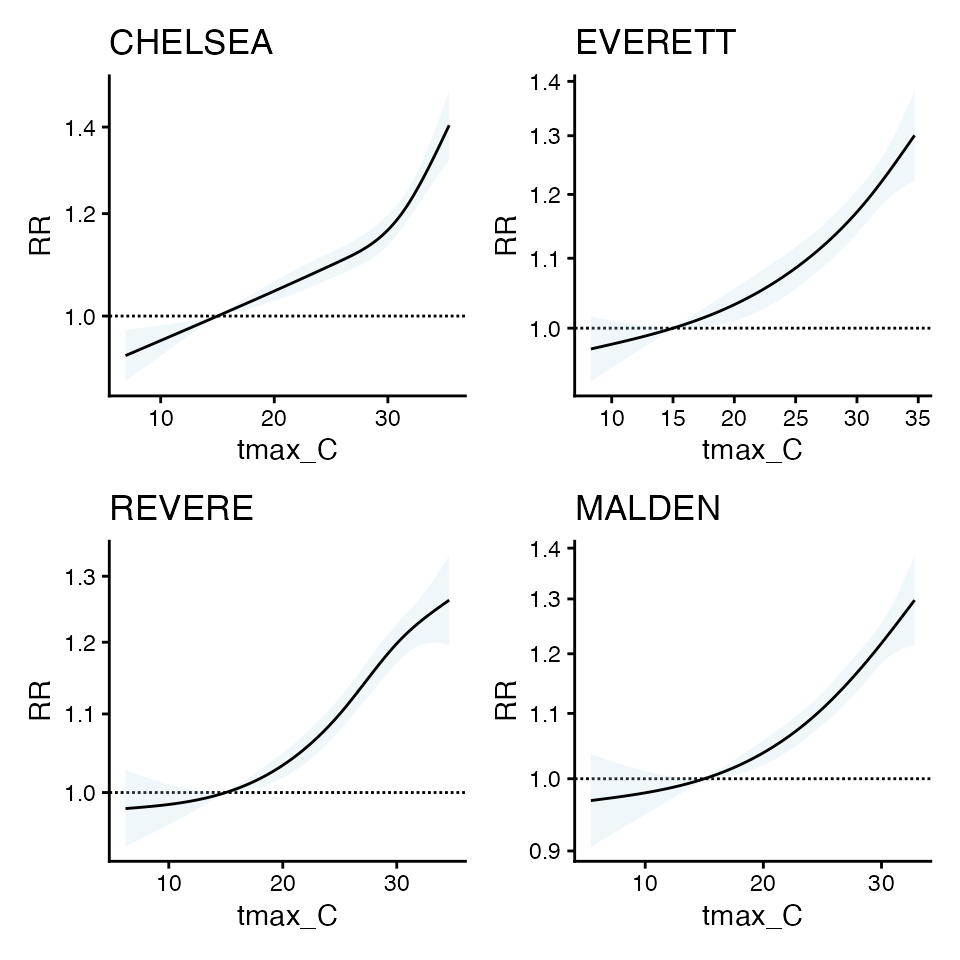
the cr coefs are similar
the orig_coefs are not, which is why beta-wise implementation of SB_DLNM method doesn’t work - because the don’t have to be the same to produce similar curves.
So, instead of forcing Beta to be similar, we can use bym2
refs:
- https://mc-stan.org/learn-stan/case-studies/icar_stan.html
- https://link.springer.com/article/10.1186/1476-072X-4-31
- https://github.com/stan-dev/example-models/blob/e5b7d9e2e9ecc375805c7e49e4a4d4c1882b5e3b/knitr/car-iar-poisson/bym2_predictor_plus_offset.stan#L4
ok here’s the ref of how LAPLACE works:
- https://mc-stan.org/cmdstanr/reference/model-method-laplace.html
- https://statmodeling.stat.columbia.edu/2023/02/08/implementing-laplace-approximation-in-stan-whats-happening-under-the-hood/
I think this makes for a good candidate because betas are normal and the model is not hierarchical
m_sb1 <- condPois_sb(exposure_mat, deaths_tbl, local_shp,
stan_type = 'mcmc',
verbose = 2,
global_cen = 15,
stan_opts = list(refresh = 200),
use_spatial_model = 'none')
#> STAN TYPE = mcmc
#> SPATIAL MODEL = none
#> -- validation passed
#> -- prepare inputs
#> CHELSEA
#> crossbasis args for geo_unit CHELSEA :
#>
#> maxlag: 5
#>
#> argvar:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: Named num [1:2] 25.8 31.3
#> ..- attr(*, "names")= chr [1:2] "50%" "90%"
#>
#> arglag:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: num [1:2] 0.878 2.095
#>
#> strata:
#> CHELSEA:yr2012:mn05:dow03
#> strata_min: 0
#>
#> EVERETT MALDEN REVERE
#> Warning in getSW(shp = shp_sf_safe, ni = 1, include_self = F): has to be one
#> polygon per row in `shp`
#>
#> -- run STAN
#> ...mcmc...
#> Running MCMC with 2 parallel chains...
#>
#> Chain 1 Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2 Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2 Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1 Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1 Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2 Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2 Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1 Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2 Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1 Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2 Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2 Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1 Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1 Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2 Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1 Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2 Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1 Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2 Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1 Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2 Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2 Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2 finished in 21.7 seconds.
#> Chain 1 Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1 Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1 finished in 24.4 seconds.
#>
#> Both chains finished successfully.
#> Mean chain execution time: 23.0 seconds.
#> Total execution time: 24.5 seconds.
#>
#> ...mcmc draws...
#> CHELSEA EVERETT MALDEN REVERE
#> -- apply estimatesCompare, first you can see that with spatial_model = F, there is similarity in beta coefs
mx
#> CHELSEA EVERETT REVERE MALDEN
#> cbv1.l1 0.0451309468 0.05298088 -0.0005224117 0.017711625
#> cbv1.l2 -0.0223211761 -0.03592669 0.0184129771 0.012490790
#> cbv1.l3 0.0873424413 0.08593669 0.1029649763 0.093454486
#> cbv1.l4 -0.0335859603 -0.03578575 -0.0337628164 -0.041517343
#> cbv2.l1 0.0852368471 0.05049362 -0.0533811289 0.039648824
#> cbv2.l2 0.0166508607 -0.11934992 0.0747314454 0.055829432
#> cbv2.l3 0.1926712791 0.18510476 0.1393985118 0.118837565
#> cbv2.l4 -0.0462482063 -0.04542133 -0.0608086198 -0.054356689
#> cbv3.l1 0.0170645385 0.07301390 0.0257165131 0.038563344
#> cbv3.l2 -0.0005616437 -0.06948122 0.0223225434 -0.002010598
#> cbv3.l3 0.1718665757 0.12512136 0.1186064940 0.130222731
#> cbv3.l4 -0.0490847643 -0.01913613 -0.0655887549 -0.044893272
m_sb1$`_`$beta_mat
#> CHELSEA EVERETT MALDEN REVERE
#> [1,] 0.046451146 0.05193203 0.017183168 -0.000424874
#> [2,] -0.024004122 -0.03424428 0.011919092 0.018004531
#> [3,] 0.087005275 0.08600062 0.093602318 0.103398072
#> [4,] -0.033260911 -0.03582986 -0.041470530 -0.033616921
#> [5,] 0.090138194 0.04626000 0.039001008 -0.053467408
#> [6,] 0.009489463 -0.11292209 0.054874194 0.072859687
#> [7,] 0.191312835 0.18591096 0.117228149 0.142018513
#> [8,] -0.042678153 -0.04681459 -0.053749416 -0.060871001
#> [9,] 0.018904632 0.07075151 0.039603114 0.025033481
#> [10,] -0.002773212 -0.06646190 -0.003032928 0.021496167
#> [11,] 0.170843688 0.12531848 0.129976780 0.119833251
#> [12,] -0.047985404 -0.02065557 -0.044806349 -0.065717577Compare with spatial model
using laplace in this case, but you could try mcmc
m_sb2 <- condPois_sb(exposure_mat, deaths_tbl, local_shp,
stan_type = 'laplace',
verbose = 2,
global_cen = 15,
stan_opts = list(refresh = 200),
use_spatial_model = 'bym2')
#> STAN TYPE = laplace
#> SPATIAL MODEL = bym2
#> -- validation passed
#> -- prepare inputs
#> CHELSEA
#> crossbasis args for geo_unit CHELSEA :
#>
#> maxlag: 5
#>
#> argvar:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: Named num [1:2] 25.8 31.3
#> ..- attr(*, "names")= chr [1:2] "50%" "90%"
#>
#> arglag:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: num [1:2] 0.878 2.095
#>
#> strata:
#> CHELSEA:yr2012:mn05:dow03
#> strata_min: 0
#>
#> EVERETT MALDEN REVERE
#> Warning in getSW(shp = shp_sf_safe, ni = 1, include_self = F): has to be one
#> polygon per row in `shp`
#>
#> -- run STAN
#> ...laplace optimize...
#> Initial log joint probability = -6739.06
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 135 -6737.26 0.000480621 0.490307 1 1 162
#> Optimization terminated normally:
#> Convergence detected: relative gradient magnitude is below tolerance
#> Finished in 0.1 seconds.
#> ...laplace sample...
#> Calculating Hessian
#> Calculating inverse of Cholesky factor
#> Generating draws
#> iteration: 0
#> iteration: 100
#> iteration: 200
#> iteration: 300
#> iteration: 400
#> iteration: 500
#> iteration: 600
#> iteration: 700
#> iteration: 800
#> iteration: 900
#> Finished in 0.6 seconds.
#> ...laplace draws...
#> CHELSEA EVERETT MALDEN REVERE
#> -- apply estimatesCompare, now you can see these are different
mx
#> CHELSEA EVERETT REVERE MALDEN
#> cbv1.l1 0.0451309468 0.05298088 -0.0005224117 0.017711625
#> cbv1.l2 -0.0223211761 -0.03592669 0.0184129771 0.012490790
#> cbv1.l3 0.0873424413 0.08593669 0.1029649763 0.093454486
#> cbv1.l4 -0.0335859603 -0.03578575 -0.0337628164 -0.041517343
#> cbv2.l1 0.0852368471 0.05049362 -0.0533811289 0.039648824
#> cbv2.l2 0.0166508607 -0.11934992 0.0747314454 0.055829432
#> cbv2.l3 0.1926712791 0.18510476 0.1393985118 0.118837565
#> cbv2.l4 -0.0462482063 -0.04542133 -0.0608086198 -0.054356689
#> cbv3.l1 0.0170645385 0.07301390 0.0257165131 0.038563344
#> cbv3.l2 -0.0005616437 -0.06948122 0.0223225434 -0.002010598
#> cbv3.l3 0.1718665757 0.12512136 0.1186064940 0.130222731
#> cbv3.l4 -0.0490847643 -0.01913613 -0.0655887549 -0.044893272
m_sb2$`_`$beta_mat
#> CHELSEA EVERETT MALDEN REVERE
#> [1,] 0.045634215 0.05115889 1.912114e-02 0.0002296362
#> [2,] -0.021347754 -0.03362789 1.150065e-02 0.0171305953
#> [3,] 0.085932504 0.08576225 9.196965e-02 0.1026762648
#> [4,] -0.033000435 -0.03697993 -4.039857e-02 -0.0336146202
#> [5,] 0.088898862 0.04896233 3.576612e-02 -0.0522570899
#> [6,] 0.020300892 -0.11182180 6.186971e-02 0.0754946284
#> [7,] 0.186678776 0.18210428 1.161405e-01 0.1371428533
#> [8,] -0.042245354 -0.04676315 -5.374222e-02 -0.0610988010
#> [9,] 0.016161670 0.07259095 3.726371e-02 0.0261401174
#> [10,] 0.001593987 -0.06659985 -7.422318e-05 0.0225049341
#> [11,] 0.172182870 0.12419511 1.292096e-01 0.1186491005
#> [12,] -0.048831973 -0.01967055 -4.505572e-02 -0.0657595895Compare with spatial model for leroux
using laplace in this case, but you could try mcmc
m_sb3 <- condPois_sb(exposure_mat,
deaths_tbl, local_shp,
stan_type = 'laplace',
verbose = 2,
stan_opts = list(refresh = 200),
use_spatial_model = 'leroux')
#> STAN TYPE = laplace
#> SPATIAL MODEL = leroux
#> -- validation passed
#> -- prepare inputs
#> CHELSEA
#> crossbasis args for geo_unit CHELSEA :
#>
#> maxlag: 5
#>
#> argvar:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: Named num [1:2] 25.8 31.3
#> ..- attr(*, "names")= chr [1:2] "50%" "90%"
#>
#> arglag:
#> List of 2
#> $ fun : chr "ns"
#> $ knots: num [1:2] 0.878 2.095
#>
#> strata:
#> CHELSEA:yr2012:mn05:dow03
#> strata_min: 0
#> Warning in condPois_1stage(exposure_matrix = single_exposure_matrix, outcomes_tbl = single_outcomes_tbl, : Centering point is outside the range of exposures in geo-unit CHELSEA: Cen = 6.90, x_b = (7.00, 36.00).
#> This means your zones are across too large of an area, or if exposure is factor there could
#> be too few events in this area, or
#> there are differences in exposures so much that the bases are quite different. Try limiting the geo-units passed in to those that are more similar, manually setting a centering point that you know each geo-unit has, or changing your exposure variable.
#> EVERETT MALDEN REVERE
#> Warning in condPois_1stage(exposure_matrix = single_exposure_matrix, outcomes_tbl = single_outcomes_tbl, : Centering point is outside the range of exposures in geo-unit REVERE: Cen = 6.20, x_b = (7.00, 35.00).
#> This means your zones are across too large of an area, or if exposure is factor there could
#> be too few events in this area, or
#> there are differences in exposures so much that the bases are quite different. Try limiting the geo-units passed in to those that are more similar, manually setting a centering point that you know each geo-unit has, or changing your exposure variable.
#> Warning in getSW(shp = shp_sf_safe, ni = 1, include_self = F): has to be one
#> polygon per row in `shp`
#>
#> -- run STAN
#> ...laplace optimize...
#> Initial log joint probability = -7000.25
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 199 -6483.58 0.0592651 2851.7 0.3124 1 214
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 399 -6440.07 9.26028e-05 1448.31 1 1 425
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 599 -6436.46 0.000542912 578.289 1 1 637
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 799 -6435.89 4.05429e-05 235.671 0.9461 0.9461 844
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 999 -6435.58 0.0001235 312.848 1 1 1051
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 1199 -6435.28 0.000121976 568.2 1 1 1269
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 1399 -6435.15 9.91154e-06 101.253 1 1 1484
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 1599 -6434.98 2.29524e-05 114.414 1 1 1694
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 1799 -6434.87 6.22773e-05 170.207 1 1 1901
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 1999 -6434.52 0.00413995 1870.72 1 1 2109
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 2199 -6433.18 0.000436944 834.056 1 1 2325
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 2399 -6432.52 2.71483e-05 204.321 1 1 2533
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 2599 -6432.35 9.54362e-05 269.67 1 1 2739
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 2799 -6432.11 4.62306e-05 597.971 1 1 2947
#> Iter log prob ||dx|| ||grad|| alpha alpha0 # evals Notes
#> 2972 -6431.94 2.16346e-06 32.6528 1 1 3130
#> Optimization terminated normally:
#> Convergence detected: relative gradient magnitude is below tolerance
#> Finished in 1.1 seconds.
#> ...laplace sample...
#> Calculating Hessian
#> Calculating inverse of Cholesky factor
#> Generating draws
#> iteration: 0
#> iteration: 100
#> iteration: 200
#> iteration: 300
#> iteration: 400
#> iteration: 500
#> iteration: 600
#> iteration: 700
#> iteration: 800
#> iteration: 900
#> Finished in 0.7 seconds.
#> ...laplace draws...
#> CHELSEA EVERETT MALDEN REVERE
#> -- apply estimatesAs you can see, lots of smoothing to a central estimate !
mx
#> CHELSEA EVERETT REVERE MALDEN
#> cbv1.l1 0.0451309468 0.05298088 -0.0005224117 0.017711625
#> cbv1.l2 -0.0223211761 -0.03592669 0.0184129771 0.012490790
#> cbv1.l3 0.0873424413 0.08593669 0.1029649763 0.093454486
#> cbv1.l4 -0.0335859603 -0.03578575 -0.0337628164 -0.041517343
#> cbv2.l1 0.0852368471 0.05049362 -0.0533811289 0.039648824
#> cbv2.l2 0.0166508607 -0.11934992 0.0747314454 0.055829432
#> cbv2.l3 0.1926712791 0.18510476 0.1393985118 0.118837565
#> cbv2.l4 -0.0462482063 -0.04542133 -0.0608086198 -0.054356689
#> cbv3.l1 0.0170645385 0.07301390 0.0257165131 0.038563344
#> cbv3.l2 -0.0005616437 -0.06948122 0.0223225434 -0.002010598
#> cbv3.l3 0.1718665757 0.12512136 0.1186064940 0.130222731
#> cbv3.l4 -0.0490847643 -0.01913613 -0.0655887549 -0.044893272
m_sb3$`_`$beta_mat
#> CHELSEA EVERETT MALDEN REVERE
#> [1,] 0.030890899 0.030891160 0.030891202 0.030891276
#> [2,] -0.008934332 -0.008934032 -0.008933796 -0.008933673
#> [3,] 0.093069451 0.093069618 0.093070202 0.093070315
#> [4,] -0.035069960 -0.035069930 -0.035069765 -0.035069589
#> [5,] 0.048175551 0.048172507 0.048173515 0.048171025
#> [6,] -0.017076972 -0.017077683 -0.017078980 -0.017078669
#> [7,] 0.151028269 0.151027837 0.151027072 0.151027367
#> [8,] -0.043569710 -0.043569786 -0.043569737 -0.043569727
#> [9,] 0.045601554 0.045601569 0.045601838 0.045601988
#> [10,] -0.018787122 -0.018787260 -0.018786989 -0.018786842
#> [11,] 0.132355975 0.132355409 0.132355763 0.132355642
#> [12,] -0.042634646 -0.042634555 -0.042634716 -0.042635042And you can also see that the leroux q value is quite
high
subset(m_sb3$`_`$stan_summary, variable == 'q')
#> # A tibble: 1 × 7
#> variable mean median sd mad q5 q95
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 q 0.911 0.999 0.234 0.000603 0.191 0.999All of the other objects associated with condPois_1stage
or condPois_2stage will also work here, along with the
_list and factor coding